Estudiantes de Educación Secundaria de Baja California (México){1}
1. Introducción, contexto y objetivos
Como es sabido, cada vez son más numerosas y frecuentes las evaluaciones a gran escala en las que se estudia y tratan de explicar las diferencias observadas en el desempeño académico de los estudiantes.
Con respecto al sistema educativo mexicano y centrados en el estudio de las variables contextuales se dispone de los siguientes trabajos: Backhoff, Bouzas, Hernández y García, 2007; Backhoff, Bouzas, Contreras, Hernández y García, 2007; Valenti, 2007; Backhoff, Andrade, Sánchez y Peón, 2008.
Centrados en el estudio de materias curriculares como las matemáticas está el trabajo de Ruíz 2009 o el de Sánchez (2009) sobre las pruebas Excale, y el de Barrera (2009) relativo a la Formación Cívica y Ética. Sobre la misma materia, pero centrado en el caso específico del Estado de Baja California son reseñables los trabajos de Carvallo, Caso y Contreras (2007) y de Caso, Hernández y Rodríguez (2009).
En esta misma línea y en virtud de un acuerdo con la Secretaría de Educación Pública del Estado de Baja California (México), la Unidad de Evaluación Educativa del Instituto de Investigación y Desarrollo Educativo de la Universidad Autónoma de Baja California ha desarrollado en el curso 2008-2009 una estrategia evaluativa integral dirigida a la población escolar de enseñanza secundaria del Estado de Baja California.
La finalidad de dicha estrategia es estudiar los factores asociados al aprendizaje y al rendimiento académico con objeto de elaborar y sugerir acciones y propuestas de mejora a los responsables del sistema educativo.
En esta línea y durante el citado curso, la estrategia evaluativa consideró la evaluación de las asignaturas de Matemáticas, Lengua Española y Formación Cívica y Ética. El rendimiento en estas materias es medido mediante las pruebas de ENLACE que se aplican con carácter censal en toda la República. Para un análisis de los factores asociados al aprendizaje del español y las matemáticas partiendo de las pruebas de ENLACE 2007 véase el ya citado trabajo de Valenti (2007).
Para la medición de los factores asociados al aprendizaje, se elaboraron cuestionarios ad hoc dirigidos a los estudiantes, docentes y directores. Estos instrumentos se aplicaron a una muestra representativa aleatoriamente seleccionada. Aunque en el apartado siguiente se va a describir con detalle el proceso de muestreo, adelantamos aquí que estos cuestionarios se aplicaron a casi 6000 estudiantes de tercero de educación secundaria pertenecientes a 65 centros escolares.
Aunque, como acabamos de afirmar, la finalidad general de esta estrategia es el diseño de propuestas y acciones de mejora, este trabajo se plantea como principal objetivo el estudio de la incidencia de estos factores asociados al aprendizaje de los estudiantes de tercero de secundaria de Baja California en su rendimiento académico en la materia de Lengua Española. Más concretamente, el interés se centra en realizar un estudio diferencial de dicha incidencia en función de las muy diversas situaciones y realidades detectadas en los centros escolares de Baja California. La hipótesis básica de trabajo es que la realidad social mexicana (y por ende la de Baja California) es tan diversa y tiene contrastes tan acentuados que las oportunidades de aprendizaje inciden de manera distinta en diferentes grupos de centros. Para contrastar esta hipótesis, en primer lugar vamos a caracterizar estos diferentes grupos de escuelas mediante la técnica de minería de datos conocida como árboles de decisión o árboles de regresión y clasificación. Posteriormente, mediante técnicas de modelización multinivel diseñaremos y validaremos un modelo explicativo del rendimiento en lengua tomando en consideración los resultados obtenidos en la fase exploratoria inicial.
La idea básica es que las condiciones, las oportunidades de aprendizaje relevantes no son las mismas para todos los estudiantes y todas las escuelas sobre todo si tomamos en consideración las acusadas diferencias en el nivel socioeconómico y cultural de las familias y la media de los centros. Dicho de otra manera: pensamos que, dentro de las variables que se pueden considerar como clásicas predictoras del rendimiento académico, hay algunas que inciden sobre el rendimiento de todos los estudiantes y centros mientras que otras sólo afectan a determinados subgrupos de la población. Si esta hipótesis se cumple, no basta con elaborar y ajustar modelos para toda la población, sino que debe realizarse un estudio diferencial centrado en estos subgrupos.
2. Método
2.1. Muestra
Como antes se ha señalado, la evaluación se realizó en una muestra representativa de estudiantes de tercero de secundaria seleccionados aleatoriamente. Es oportuno señalar que el Estado de Baja California consta de cinco municipios y que los centros escolares en los que se imparte la educación secundaria pueden ser de diferentes modalidades: secundaria general, técnica, telesecundaria y privada. Excepto en el caso de la privada, el resto reciben financiación pública.
Según datos del sistema educativo estatal, la distribución de la población escolar de tercero de secundaria es la que aparece en la tabla 1 en la que se observa la distribución por municipios y tipos o modalidades de escuelas del total de centros (427) y estudiantes (48.682) para este grado escolar en Baja California.
Tabla 1. Alumnos y centros escolares por municipio y tipo de escuela. Fuente: Sistema Educativo Estatal
|
GENERAL |
PRIVADA |
TECNICA |
TELESECUNDARIA |
Total |
ENSENADA |
4134 |
417 |
2140 |
663 |
7354 |
MEXICALI |
10874 |
1118 |
2264 |
72 |
14328 |
PLAYAS DE ROSARITO |
1024 |
141 |
458 |
87 |
1710 |
TECATE |
1263 |
66 |
121 |
146 |
1596 |
TIJUANA |
13936 |
2478 |
6223 |
1057 |
23694 |
Total |
31231 |
4220 |
11206 |
2025 |
48682 |
| Fuente: Sistema Educativo Estatal | |||||
Tomando en cuenta estos estratos, la selección de las escuelas y estudiantes fue determinada mediante el método de muestreo por conglomerados en tres etapas, con probabilidades proporcionales al tamaño, teniendo como unidad última de selección la escuela y como unidad de observación al estudiante de tercero de secundaria.
En función de ello, se estableció un tamaño de muestra de 71 escuelas que representa el 16.6% del total de secundarias del estado. Finalmente, de acuerdo con los registros del Sistema Educativo Estatal el número de alumnos inscritos en los grupos de tercer año de secundaria de las 71 escuelas secundarias seleccionadas fue de 8,375, lográndose encuestar solamente a 6,317 de ellos, lo que representa el 75.4 % de cobertura de la muestra aleatoria. Por último, al integrar las bases de datos de ENLACE con las de elaboración propia, el número final de centros fue de 65 y el de estudiantes de 6.211 que representan el 74.2% de la muestra estimada. En la tabla 2 se detalla la distribución de dichos estudiantes en cuanto a su sexo, edad, municipio, tipo de escuela y turno escolar. Hay que hacer notar que estos son los datos iniciales del estudio. La matriz de datos con la que vamos a operar es ligeramente distinta una vez depurada de algunos errores y de escuelas con muy bajo número de estudiantes (menos que 10).
Tabla 2. Características de los estudiantes (n=6211)
Variable |
|
n |
Porcentaje |
Sexo |
Femenino |
2,971 |
50.0 |
Masculino |
2,973 |
50.0 |
|
Edad |
13 |
9 |
0.1 |
14 |
1,649 |
27.4 |
|
15 |
3,582 |
59.6 |
|
16 |
679 |
11.3 |
|
17 o más |
91 |
1.5 |
|
Municipio |
Ensenada |
1,284 |
20.7 |
Mexicali |
1,340 |
21.3 |
|
Rosarito |
371 |
6.2 |
|
Tecate |
332 |
5.4 |
|
Tijuana |
2,884 |
46.3 |
|
Tipo de secundaria |
Privada |
630 |
10.1 |
General |
3,704 |
59.6 |
|
Técnica |
1,675 |
27.0 |
|
Telesecundaria |
202 |
3.3 |
|
Turno escolar |
Matutino |
4,748 |
76.4 |
Vespertino |
1,463 |
23.6 |
2.2. Variables e instrumentos de medida
Como anteriormente se ha señalado, de las tres materias cuyo rendimiento fue medido mediante las pruebas de ENLACE, en este estudio nos vamos a centrar en Lengua Española. En la página web de la Secretaría de Educación Pública del Gobierno Federal mexicano (http://www.enlace.sep.gob.mx/gr/) se puede encontrar información detallada sobre el programa ENLACE, las pruebas empleadas y los resultados obtenidos. Las pruebas de ENLACE son pruebas objetivas y estandarizadas, de aplicación censal y controlada. Su diseño se alinea al currículum de la educación básica del sistema educativo mexicano y pretenden informar en qué medida los estudiantes adquirieron los conocimientos y habilidades que establece dicho currículum.
Para la medición de los factores asociados al aprendizaje se diseñaron y aplicaron cuestionarios ad hoc dirigidos a estudiantes, profesores y directores. En este estudio vamos a emplear la información proveniente del cuestionario del alumno. El mismo es un instrumento de autoinforme conformado por 58 ítems que exploran las oportunidades para aprender que le ofrecen a un estudiante los diferentes contextos donde interactúa cotidianamente. El cuestionario cuenta con tres secciones: a) contexto familiar; b) antecedentes académicos; y c) contexto escolar.
Desde una perspectiva multinivel, la información proporcionada por este cuestionario nos permite recabar datos a dos niveles: estudiante y centro escolar. Para el segundo nivel se han calculado valores agregados para cada unidad del segundo nivel tomando en consideración los valores promedios de las variables relevantes.
Dichas variables han sido las siguientes:
Estudiante:
- Personales y sociodemográficas: sexo, edad, edad normativa, lugar nacimiento, lugar de residencia, años de residencia en la entidad.
- Nivel socioeconómico y cultural: indicadores sobre el nivel socioeconómico de las familias (NSE), sobre el consumo de bienes culturales, nivel de escolaridad de padres y madres, puestos de trabajo, nivel profesional. Se calcula un índice compuesto individual (familiar).
- Apoyo e implicación familiar en las tareas escolares: indicadores sobre el grado y manera en que las familias se implican y apoyan al estudiante en las tareas y sobre el nivel y forma en que motivan al estudiante. Se calcula un índice compuesto.
- Adaptación e integración escolar: Razones para estudiar la educación secundaria. Relación profesor-alumno y alumnos entre sí e indicadores sobre la calidad de la misma. Se calcula un índice compuesto.
- Lectura: horas dedicadas a la lectura, gusto y afición por la lectura, compromiso lector.
- Escolaridad: asistencia a preescolar, días que falta a la escuela, retrasos en la asistencia al centro. Horas dedicadas a hacer las tareas de español, número de tareas realizadas.
- Cuestiones sobre el docente de lengua española (percibidas por el estudiante): actividad, puntualidad, faltas, técnicas de motivación que emplea, estrategias y usos docentes.
- Equipamientos del centro: enumeración, estado y frecuencia de uso.
2.3. Preparación de datos y archivos
Una vez elaborados mediante análisis de componentes principales los índices compuestos correspondientes a los diferentes constructos, se procede a la fusión de los dos archivos de fuentes de datos parciales: pruebas de ENLACE y cuestionario de estudiantes. Este proceso de fusión de datos se realiza empleando los identificadores disponibles de estudiantes y centros.
Pero aquí nos encontramos ya con una primera característica diferencial del sistema educativo mexicano. Nos referimos a la existencia de dos turnos: matutino y vespertino. En Baja California casi la cuarta parte de los estudiantes de secundaria acuden a clase por las tardes. Son numerosos los centros (todos de titularidad pública) que duplican turno y que reciben estudiantes tanto a la mañana como a la tarde.
Pero en el caso en que en un centro se dé esta situación, ambos turnos lo único que comparten, lo único que tienen en común, son las instalaciones físicas del centro escolar. El resto es completamente diferente: por supuesto los estudiantes, pero también los docentes y la dirección. Cuando en una escuela se da esta circunstancia, este hecho nos ha llevado a tomar la decisión de considerar el turno matutino y el vespertino como dos centros educativos distintos.
Así, en la tabla 3 se pueden apreciar las diferencias que se dan entre ambos turnos en variables clave como son el propio rendimiento en español, el nivel socioeconómico familiar y el nivel socioeconómico medio de las escuelas. Estas diferencias resultan significativas (p<.01) por lo que los estudiantes que acuden a estudiar por la mañana son de un nivel socioeconómico y cultural mayor que los de la tarde y obtienen mejor rendimiento en la prueba de ENLACE de lengua española (28 puntos).
Esto nos reafirma en la decisión de considerar a los diferentes turnos como centros distintos y para ello se elaboró un nuevo identificador de centro que incorpora el de la escuela y el del turno.
Tabla 3. Diferencias según el turno
Turno al que asiste |
|
Calificación en Español |
NSE familiar |
NSE medio de la escuela |
1 Matutino |
N |
4748 |
3979 |
4748 |
Media |
519,56 |
,05 |
,038 |
|
Desv. típ. |
99,41 |
1,02 |
,65 |
|
2 Vespertino |
N |
1463 |
1204 |
1463 |
Media |
491,41 |
-,17 |
-,18 |
|
Desv. típ. |
90,17 |
,90 |
,39 |
|
Total |
N |
6211 |
5183 |
6211 |
Media |
512,93 |
,00 |
-,01 |
|
Desv. típ. |
98,04 |
1,00 |
,61 |
Finalmente, una vez eliminados los centros con menos de 10 alumnos, el archivo de trabajo resultante contiene 6.185 estudiantes agrupados en 71 centros-turnos distintos. Son 13 las escuelas que duplican turno, 31 las que sólo imparten por la mañana y 4 las que en esta muestra sólo imparten por la tarde.
A continuación, y con objeto de disponer de variables del nivel de centro, se generan variables agregadas mediante el cálculo de los promedios de las variables del nivel 1 segmentando por el identificador de centro-turno. De esta forma, y aunque la fuente de información sea el estudiante a través del cuestionario, se dispone de variables relativas al centro-turno como el nivel socioeconómico medio de cada escuela, el promedio del clima escolar, el de las faltas de los profesores de español, etc. que completan las habituales como el turno o la titularidad.
2.4. Análisis de datos y resultados
2.4.1. Estudio mediante técnicas de segmentación
Con este archivo de trabajo se comienza el análisis empleando técnicas de minería de datos, en concreto técnicas de segmentación también conocidas como árboles de decisión o árboles de regresión y clasificación.
Se trata de un conjunto de técnicas que permiten definir y validar modelos de forma que se pueda determinar qué variables (predictoras) inciden o explican los cambios de una variable dependiente. Son técnicas estadísticas de la familia de la regresión o el análisis discriminante, pero tienen la ventaja de que tanto la variable criterio como las predictoras pueden ser de cualquier tipo (cuantitativas o cualitativas).
El principio básico de operación consiste en dividir progresivamente un conjunto en clases disjuntas. Para ello, una vez definida la variable dependiente, se efectúa una partición del grupo original en 2 ó más subgrupos atendiendo a los valores de la variable predictora que más se asocie a la variable dependiente. Una vez efectuada esta primera segmentación, el proceso se reinicia en cada uno de los subgrupos y finaliza cuando se alcanza alguno de los criterios de parada establecidos a priori. El resultado de un proceso de tales características se plasma en un árbol de decisión que muestra la estructura y relaciones de las variables para cada uno de los segmentos o subgrupos.
Existen varios algoritmos o procedimientos de generación de árboles de decisión. En el presente estudio se empleó el método CHAID (CHi-squared Automatic Interaction Detector), desarrollado por Kass (1980), y en concreto una variante del mismo denominado CHAID exhaustivo, desarrollado por Bigs, de Ville y Suen (1991). La razón básica es que es aplicable a cualquier tipo de variables, tanto dependiente como predictoras y las soluciones que ofrece no son binarias sino que para cada nivel de segmentación, el algoritmo busca la clasificación óptima generando tantos subgrupos como sean necesarios.
En función de los objetivos de este trabajo, este conjunto de técnicas resultan especialmente adecuadas por varias razones: en primer lugar, asumiendo un modelo clásico de dependencia en el que la variable criterio es el rendimiento académico, en este caso en lengua española, estas técnicas nos permiten elaborar modelos con todo tipo de variables predictoras. Segundo, tanto el procedimiento de segmentación como la presentación gráfica de resultados permiten el estudio de relaciones y efectos de interacción entre variables para subgrupos específicos, y esto, como inmediatamente vamos a ver es de especial importancia para nosotros. En esta línea, Dudley, Dilorio y Soet (2000) afirman que las técnicas de segmentación, y más específicamente el algoritmo CHAID por el que hemos optado, resultan útiles para detectar y explicar la interacción de datos categóricos, especialmente en el caso de interacciones complejas entre dos o más predictores. En Lizasoain y otros (2003) realizamos una primera aproximación al empleo de estas técnicas estadísticas en la evaluación del rendimiento en lenguas en un estudio evaluativo en la Comunidad Autónoma Vasca.
Al realizar el análisis de segmentación habiendo definido como variable criterio la calificación en la prueba de ENLACE en español y como predictoras todas las demás, obtenemos un árbol de 9 nodos siendo la primera variable de segmentación la variable de identificación de centro-turno a la que antes se ha hecho referencia. En la figura 1 se muestra la apariencia de este primer nivel del árbol de decisión con los 9 nodos, los 9 subgrupos de centros escolares. Por evidentes razones de espacio, se ha reducido el tamaño del gráfico y no son legibles las etiquetas que identifican los centros escolares que conforman cada nodo.
Figura 1. Primer nivel de segmentación según centro-turno
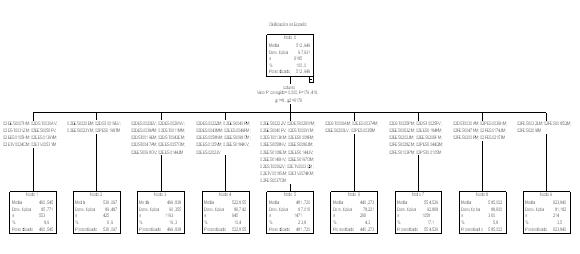
El nodo cero, el nodo raíz, está formado por toda la muestra: por los 6185 estudiantes de los 71 centros (considerando el turno) cuya media en español es de 512.95. Para cada uno de los 9 nodos del primer nivel, el gráfico proporciona el número de casos, la media y la desviación típica en lengua española de cada subgrupo. En la tabla 4 se ha resumido y ordenado esta información añadiendo además los parámetros del nivel socioeconómico (NSE) medio de los centros escolares de cada subgrupo.
Tabla 4. Características de los 9 nodos iniciales
Nodo CHAID exhaustivo |
Número de estudiantes |
Número de |
Media |
Desv. típica |
Media |
Desv. típica |
1 |
266 |
4 |
440,27 |
78,22 |
-0,4532 |
0,62 |
2 |
553 |
8 |
460,54 |
85,77 |
-0,2963 |
0,42 |
3 |
1471 |
17 |
481,72 |
87,01 |
-0,3208 |
0,48 |
4 |
1193 |
10 |
499,84 |
90,35 |
-0,2059 |
0,24 |
5 |
645 |
9 |
522,85 |
86,74 |
-0,4313 |
0,29 |
6 |
425 |
4 |
536,09 |
89,48 |
0,2541 |
0,20 |
7 |
1058 |
10 |
554,53 |
92,87 |
0,4527 |
0,42 |
8 |
360 |
6 |
585,00 |
88,60 |
0,8209 |
0,17 |
9 |
214 |
3 |
623,84 |
81,18 |
1,4597 |
0,17 |
Total |
6185 |
71 |
512,95 |
97,93 |
-,0138 |
0.63 |
Antes de comentar los datos de esta tabla y en general este primer resultado, es preciso hacer unas consideraciones previas sobre el procedimiento. Las técnicas de segmentación proceden analizando todas las variables predictoras con el objetivo de determinar cuál de ellas -y qué partición de la misma- es la que maximiza la diferencia entre los grupos con respecto a la variable criterio. Pues bien, en este caso ésta es la variable identificadora centro-turno. Esto quiere decir que de entre todas las variables predictoras, es decir, todas las del archivo menos la dependiente, ésta es la que genera una mayor diferencia entre los grupos con respecto al rendimiento en español. Es la que más se asocia. Ninguna otra agrupación atendiendo a los valores de otra variable predictora es capaz de generar una diferencia mayor, de obtener un mayor valor de F.
Esto supone que, de cara a explicar las diferencias existentes en el rendimiento en lengua española, el centro escolar es clave. Es el elemento que más contribuye a diferenciar niveles de rendimiento. Hasta aquí no hay nada nuevo pues la importancia del efecto del centro escolar está ampliamente documentada en la literatura.
Como antes se ha comentado, se midieron e incorporaron al estudio numerosas variables del nivel del centro escolar, pero el hecho de que –de todas ellas- sea este identificador la primera variable que segmenta indica que el centro escolar como unidad funcional y organizativa es el elemento clave por encima de cualquiera de los aspectos parciales del mismo tales como la modalidad pública o privada, el clima escolar, la plantilla docente, el nivel socioeconómico medio, etc.
Por tanto, estos 9 nodos constituyen la clasificación óptima de los 71 centros en función de la puntuación en lengua. Pero una vez dicho esto, cabe preguntarse cuáles son los factores de centro que más contribuyen a explicar esta clasificación. Una posible vía para dar respuesta consiste en examinar las características de los colegios de cada uno de los 9 subgrupos. Más adelante haremos una aproximación en esta línea.
Pero las técnicas de segmentación también proporcionan una posible vía de análisis. Como no es muy frecuente que los identificadores operen como variables predictoras, en un segundo proceso el identificador centro-turno se eliminó del modelo y se repitió el análisis obteniendo como resultado que el nivel socioeconómico medio de los centros resultó ser la primera variable de segmentación (figura 2).
Figura 2. Primer nivel de segmentación según NSE medio una vez eliminado centro-turno
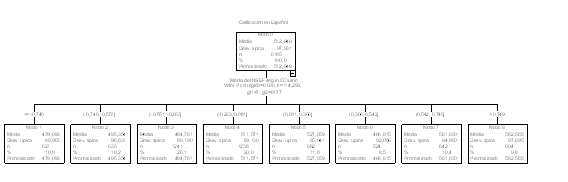
El hecho de que, una vez eliminado del modelo el identificador de centro-turno, sea ésta la primera variable que segmenta indica que, de todas las posibles variables de centro, es el nivel socioeconómico medio de los estudiantes que acuden al centro la variable que más peso tiene. Y eso es fácilmente comprobable si se observa la tabla 4 ó los 8 nodos de la figura 2. Salvo excepciones, como el nodo 5 de la tabla 4 ó el 6 de la figura 2, a mayor NSE medio del centro mayor puntuación media en lengua española. Es una correlación elevada lo que denota que entre todas las variables de centro ésta es la más importante; pero el hecho de que no sea perfecta, de que haya nodos que no se ajustan a la pauta, indica que hay además otros factores que también inciden y explican parte de la varianza del rendimiento.
Las diferencias según el NSE medio son claras y también lo son en función del tipo de escuela (pública/privada) o el turno al que acuden los estudiantes tal y como muestran las tablas 5 y 6 respectivamente en las que aparecen las frecuencias observadas y esperadas.
Tabla 5. Tabla de contingencia de los 9 nodos y la titularidad de los centros
Titularidad |
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
Privada |
Observada |
1 |
13 |
1 |
0 |
18 |
48 |
180 |
138 |
214 |
Esperada |
54,8 |
42,1 |
118,2 |
63,9 |
145,8 |
26,4 |
104,9 |
35,7 |
21,2 |
|
Pública |
Observada |
552 |
412 |
1192 |
645 |
1453 |
218 |
878 |
222 |
0 |
Esperada |
498,2 |
382,9 |
1074,8 |
581,1 |
1325,2 |
239,6 |
953,1 |
324,3 |
192,8 |
Tabla 6. Tabla de contingencia de los 9 nodos y el turno de los centros
Turno |
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
Matutino |
Observada |
311 |
352 |
943 |
504 |
933 |
188 |
917 |
360 |
214 |
Esperada |
422,2 |
324,5 |
910,8 |
492,4 |
1123,0 |
203,1 |
807,7 |
274,8 |
163,4 |
|
Vespertino |
Observada |
242 |
73 |
250 |
141 |
538 |
78 |
141 |
0 |
0 |
Esperada |
130,8 |
100,5 |
282,2 |
152,6 |
348,0 |
62,9 |
250,3 |
85,2 |
50,6 |
Como se puede apreciar, los cuatro primeros nodos, los que agrupan a estudiantes de más bajo rendimiento, se caracterizan por tener un NSE medio bajo, ser mayoritariamente centros públicos y con una mayor proporción de centros vespertinos. Por el contrario, los cuatro nodos de más altas puntuaciones en español concentran mayores proporciones de centros privados en turno matutino y con un NSE medio mayor. Estas tendencias se acentúan cuanto mayor (o menor) sea la puntuación en español de forma que prácticamente no hay centros vespertinos en los nodos altos ni estudiantes que acudan a centros privados en los nodos bajos (ver casillas sombreadas). El nodo central, el quinto, se aparta de la tendencia general puesto que con un NSE medio bajo (el segundo más bajo), obtiene una puntuación media en rendimiento. Los sujetos y centros que conforman este grupo podrían ser ejemplos de resiliencia académica aunque para probar esta hipótesis se requiere un estudio pormenorizado de los mismos que excede de los objetivos de este trabajo.
Las técnicas de segmentación no sólo proporcionan una clasificación de los centros escolares en función del rendimiento. Si se opta por que el algoritmo continúe desarrollando el árbol de clasificación, nos encontramos con un modelo de clasificación y regresión que permite observar el efecto de las variables predictoras sobre el rendimiento en lengua española.
Así, en el modelo elaborado por CHAID exhaustivo, en el segundo nivel, y para cada uno de los 9 nodos iniciales, se observa que las variables de segmentación son reactivos concretos pertenecientes a constructos como los siguientes: clima escolar (razones para ir a secundaria, me siento incómodo en mi escuela), nivel socioeconómico o cultural de la familia, gusto por la lectura, motivación y apoyo familiar, puntualidad del profesor, etc. (en esta ocasión el árbol es demasiado complejo y de difícil apreciación por lo que se ha optado por describirlo).
En resumen, el modelo propuesto incorpora las variables que se suelen considerar predictores habituales del rendimiento académico. Algunas de estas variables aparecen con una cierta frecuencia, en diversos niveles y en todas las regiones del árbol (como es el caso del NSE medio de los centros, reactivos del clima escolar o algunos indicadores de NSE o cultural familiar). Esto es un indicador de la importancia relativa de las mismas dentro del modelo explicativo.
Figura 3. Segundo nivel de segmentación para el nodo 1
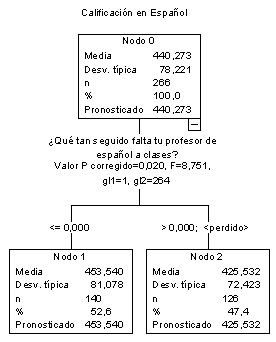
Pero hay otro conjunto de variables que aparecen sólo en algunos niveles más profundos del árbol o en algunas regiones. Por ejemplo, la figura 3 muestra el segundo nivel de segmentación para el nodo 1 que agrupa los 266 casos que obtienen la menor puntuación en lengua (440.273). Aquí la primera variable de segmentación no es ni el clima escolar ni ninguna de las variables antes apuntadas y que son habituales en modelos explicativos. Se trata de una variable ligada específicamente al cumplimiento formal del horario por parte del profesor. Como puede observarse, en aquellos casos en que el docente falta habitualmente a clase la media desciende hasta los 425,532 puntos.
Este es un ejemplo del comportamiento de este tipo de variables en estos casos. Su capacidad de segmentación opera exclusivamente en algunos subgrupos específicos de sujetos. Y lo que aquí aparece es que para grupos pequeños pero muy diferenciados con respecto a la puntuación en lengua española, aparecen variables predictoras muy distintas. En algunos casos (de rendimiento bajo) aparecen variables ligadas con el cumplimiento formal del docente o del estudiante (puntualidad, falta de asistencia) o el estado físico de las aulas o los sanitarios. En otros surgen (y con relación inversa) la existencia o uso de determinadas tecnologías educativas.
Tal y como se apuntaba anteriormente, en el sistema educativo de Baja California conviven realidades sociales, culturales y económicas muy heterogéneas. Esto hace que las diferencias entre centros escolares sean muy acusadas de forma que junto a centros escolares de muy alto nivel nos encontramos con otros que se encuentran en el otro extremo de la escala. Esto hace que sea difícil encontrar y ajustar un único modelo para realidades sociales tan dispares, pues se observan dos conjuntos de indicadores o predictores que operan de forma distinta en diferentes subgrupos de centros:
- En primer lugar, hay variables con gran capacidad de incidencia en el rendimiento académico que aparecen como variables de segmentación de forma repetida en numerosos niveles y nodos. Tal es el caso, por ejemplo, del nivel socioeconómico o cultural o el clima escolar.
- Pero junto a éstas, hay un segundo conjunto de variables que operan de forma casi exclusiva en algunos subgrupos de algunos niveles, habitualmente en los nodos extremos. Y así, en los nodos altos surgen cuestiones propias de sistemas educativos avanzados (uso de recursos tecnológicos, conexiones en el aula a Internet, etc.), mientras que en los bajos aparecen otras que se señalan como oportunidades básicas y que están más ligadas al cumplimiento efectivo del currículum, a la asistencia y puntualidad de profesores y alumnos o al estado físico de las instalaciones escolares.
2.4.2. Modelización mediante regresión multinivel
Consecuentemente con lo anteriormente expuesto, a continuación se procede al diseño y ajuste de un modelo explicativo del rendimiento en lengua española. Dado que los datos presentan una estructura anidada (estudiantes en centros escolares), y vista además la importancia que el centro-turno tiene como primera variable de segmentación, parece claro que para este fin se ha de realizar una aproximación multinivel mediante modelos jerárquicos lineales.
Una de las utilidades más relevantes de los árboles de decisión es el uso de los mismos para seleccionar variables relevantes para modelos predictivos más rigurosos por lo que, en aplicación de la misma, se consideran como variables candidatas a predictores aquellas que en los árboles han mostrado una alta capacidad discriminativa bien porque hayan aparecido en niveles iniciales de los árboles, bien porque aparezcan con frecuencia para determinados nodos en diversos niveles.
Posteriormente, y de cara a un análisis diferencial de los subgrupos más extremos, se tomarán en consideración también aquellas variables que sólo hayan aparecido en algunos niveles de segmentación de estos nodos.
En consecuencia, para el diseño y ajuste de un modelo multinivel de toda la muestra las variables consideradas han sido:
Variable dependiente: calificación en la prueba de ENLACE de Lengua Española. Es una puntuación normalizada de media 500 y desviación típica 100.
Variables predictoras del primer nivel (estudiante):
- Género de los estudiantes codificada como 0 (cero) para los estudiantes masculinos y 1 (uno) para las chicas.
- Trabajo remunerado: 0 no trabaja, 1 sí.
- Gusto por la lectura: 0, no gusta; 1, gusto moderado; 2, gusto acusado.
- Rendimiento previo en lengua española medido por las calificaciones en esta materia del curso anterior en una escala que va de 0 a 4.
- Nivel socioeconómico familiar. Puntuación resultante de un análisis de componentes principales (ACP) realizado sobre los reactivos relativos a indicadores sociales, económicos y culturales de la unidad familiar. Es una escala tipificada con media 0 y desviación típica 1.
- Clima escolar. Puntuación resultante de un ACP efectuado sobre los reactivos relativos al clima en el aula y en el centro, la relación con los compañeros y los docentes. Es una escala tipificada con media 0 y desviación típica 1.
Adicionalmente, y de cara al estudio diferencial de los subgrupos extremos se consideraron:
- Puntualidad del profesor de español. Juicio que el estudiante expresa sobre el nivel de puntualidad del docente en una escala que va desde 0 (nada puntual) a 3 (muy puntual).
- Faltas de asistencia del profesor de español. Juicio que el estudiante expresa sobre las faltas de asistencia a clase del docente en una escala que va desde 0 (nunca falta) a 3 (siempre o casi siempre falta). Nótese que estas dos variables relativas al cumplimiento formal del docente tienen escalas opuestas, inversa la puntualidad, positiva la del nivel de asistencia.
Variables predictoras del segundo nivel (centro-turno):
- Turno del centro escolar: 0, matutino; 1, vespertino.
- Titularidad del centro escolar: 0, privada; 1 pública.
- Nivel socioeconómico medio del centro. Promedio para cada centro-turno del nivel socioeconómico familiar de los estudiantes de dicho centro.
- Clima escolar medio del centro. Promedio para cada centro-turno del clima escolar percibido por los estudiantes de dicho centro.
Al igual que antes, para el estudio de los subgrupos extremos:
- Puntualidad media de los profesores de español. Promedio para cada centro-turno de la puntuación asignada por los estudiantes de dicho centro al nivel de puntualidad de su docente.
- Nivel medio de asistencia de los profesores de español. Promedio para cada centro-turno de la puntuación asignada por los estudiantes de dicho centro al nivel de asistencia de su docente.
Lógicamente, en estas variables agregadas del segundo nivel, la escala es la misma que en las correspondientes del primer nivel.
Modelo HLM
Mediante el proceso habitual y empleando el programa HLM, se procede a elaborar y validar un modelo jerárquico. Dicho modelo incluye los efectos significativos, es decir, se enfoca el problema desde un punto de vista exploratorio y no buscando el modelo más parsimonioso.
El resultado es el siguiente:
Puntuación en español = 443,21 +
+ 13,53 * Sexo (varón = 0) +
- 16,17 * Trabaja (no = 0) +
+ 30,27 * Gusto por la lectura (no = 0, poco = 1, mucho = 2) +
+ 14,03 * Calificación en español en 2º Primaria (0 a 4) +
+ 4,43 * NSE Familiar (-3,26 a 2,69) +
+ 39,20 * NSE Escuela (-1,76 a 1,53) +
+ 28,83 * Clima escolar (-0,76 a 1,34)
Parte aleatoria:
Varianza entre escuelas: 682,46
Varianza intra-escuelas : 6919,98
Controlando la calificación en Lengua española en 2º de Secundaria, los resultados del modelo indican que la puntuación media en Lengua española de los estudiantes varones de 3º de Secundaria que no trabajan y no les gusta leer, cuyo NSE familiar y escolar son medios, al igual que el clima escolar, es de algo más de 440 puntos (recuérdese que la media es aproximadamente 500 y la desviación típica 100). A ello hay que añadir algo más de 13 puntos a las alumnas; además, a los estudiantes que trabajan hay que restarles algo más de 16 puntos y añadir más de 60 puntos a los estudiantes a los que gusta la lectura. Por otra parte por cada punto de incremento del NSE familiar, el incremento en la puntuación en Lengua española resulta ser de casi 4,5 puntos (téngase presente que los valores del NSE Familiar oscilan entre -3 y 3 aproximadamente); el efecto del NSE de la Escuela (éste oscila en punto y medio alrededor de la media) es más acusado, pues ahora cada punto de incremento en él produce un incremento de casi 40 puntos en la puntuación en Lengua española. Por su parte, 1 punto de incremento en el Clima escolar global de la escuela (que escila alrededor de la media en un punto aproximadamente) origina un incremento de casi 30 en Lengua.
La parte aleatoria del modelo consiste en que la varianza entre escuelas es de 682, 46 y la varianza intra-escuelas, 6919,98; por lo tanto la correlación intra-clases es del 9% aproximadamente.
Los resultados obtenidos en este proceso de modelización, nos muestran un conjunto de predictores y una ecuación multinivel que, grosso modo, no puede considerarse muy distinta de los resultados obtenidos en estudios similares.
En el primer nivel, el género de los estudiantes muestra el habitual efecto positivo para las chicas y el efecto negativo de simultanear estudios y trabajo no merece comentario adicional. Es igualmente sabido que el rendimiento académico previo es un buen predictor del rendimiento actual y lo mismo ocurre con el nivel socioeconómico familiar. Por último, el gusto por la lectura es un importante factor de éxito en una materia como la lengua española y, aunque las escalas no sean directamente comparables, su efecto se puede equiparar al del nivel socioeconómico familiar. Resultados similares encontramos en un modelo jerárquico realizado para el estudio longitudinal de los efectos de modelos lingüísticos propios del sistema educativo vasco sobre el rendimiento en español (Santiago y otros, 2008).
En el nivel de los centros escolares nos encontramos sólo con dos variables: la media del nivel socioeconómico y la media del clima escolar. Ambas tienen un importante efecto directo sobre el rendimiento en español, especialmente el nivel socioeconómico medio. A este respecto, se debe reconocer el impacto de las diferencias socioeconómicas y culturales en el rendimiento de los estudiantes de Baja California y del propio sistema educativo mexicano al igual que ocurre en otros países y sistemas educativos. De la misma manera, se confirma también el efecto contextual (Willms, 1986; Rumberger & Willms, 1992; Willms, 2003; Willms, 2004; Tajalli & Opheim, 2004; Howley & Howley, 2004; Warschauer et al., 2004; Willms, 2006; Lizasoain y otros, 2007) de forma que el nivel socioeconómico medio (NSE) de las escuelas tiene mucho peso a la hora de explicar las diferencias de rendimiento.
Puede llamar la atención el hecho de que no aparezca la titularidad del centro o el turno, aunque es altamente probable que los efectos de estas variables se hayan subsumido en el del nivel socioeconómico medio. Por último, las variables relativas al cumplimiento formal de los docentes tanto del nivel 1 como del 2, no han resultado significativas.
Estudio diferencial
Una vez elaborado y ajustado un modelo para la totalidad de la muestra, se aborda el estudio diferencial de los subgrupos extremos. La razón es, como antes se ha visto, que en el proceso de segmentación en los nodos de estos subgrupos operan como variables de alta capacidad discriminativa algunas que no aparecen en otros lugares del árbol. Con objeto de realizar una primera aproximación a este enfoque diferencial, se seleccionan los 480 casos pertenecientes a los nodos 1 y 9 que, como se ha dicho, tienen respectivamente las puntuaciones medias más baja y alta en lengua española.
El nodo 1 está compuesto por los 266 estudiantes que, agrupados en 4 centros, obtienen le promedio más bajo en lengua española (440,27); mientras que el nodo 9 lo componen los 214 estudiantes pertenecientes a 3 centros y obtienen un promedio de 623,84.
En las tablas 7 y 8 se caracterizan ambos subgrupos en función de distintas variables. Es reseñable el hecho de que todos los centros del nodo 9 sean de titularidad privada y que ninguno imparta docencia en turno vespertino. Igualmente se observan otras diferencias importantes: en el nodo 1 hay mayor proporción de chicos que de chicas lo que probablemente se deba a una mayor presencia de estudiantes repetidores entre los que los chicos son mayoritarios. También es acusada la diferente proporción entre los que declaran trabajar en el nodo 1 (68, casi el 30%) frente a los 18 (casi el 9%) que están en la misma situación en el nodo 9. Por último las diferencias en el nivel de gusto por la lectura, en el clima escolar, en el NSE y en el cumplimiento formal son siempre en sentido favorable al nodo 9. Todas estas diferencias resultan significativas con una p<0,01.
Tabla 7. Caracterización de los nodos 1 y 9 (I)
Nodos (%) |
Género |
Trabajo |
Gusto lectura |
Titularidad |
Turno |
||||||
H |
M |
No |
Sí |
No gusta |
Poco |
Mucho |
Privada |
Pública |
Matut. |
Vesp. |
|
1 |
57,4 |
42,6 |
70,8 |
29,2 |
22,6 |
65,5 |
11,9 |
18 |
82 |
70,7 |
29,3 |
9 |
50,7 |
49,3 |
91,2 |
8,8 |
17,7 |
56,5 |
25,8 |
100 |
0 |
100 |
0 |
Tabla 8. Caracterización de los nodos 1 y 9 (II)
Nodos |
Número |
Número |
Media |
Media |
Media Clima escolar |
Puntualidad |
Asistencia |
1 |
266 |
4 |
440,27 |
-0,4532 |
-0,0791 |
1,95 |
0,57 |
9 |
214 |
3 |
623,84 |
1,4597 |
0,8229 |
2,32 |
0,18 |
Pues bien, a la vista de estas diferencias y de la presencia en estos nodos de nuevas variables relevantes, ahora se trata de probar la hipótesis inicialmente apuntada de que los modelos explicativos del rendimiento en lengua española serán distintos para estos grupos con respecto al elaborado para el total de la muestra.
Para ello pueden plantearse varias vías analíticas. Una primera consistiría en segmentar el archivo de datos en función del nodo tratando y estudiando cada nodo por separado formulando y ajustando un modelo para cada uno. Pero esto no es una aproximación adecuada porque estos nodos no constituyen una agrupación natural de las unidades sino que se han establecido -mediante los árboles de decisión- en función precisamente de las puntuaciones en rendimiento en lengua española. Esto supondría realizar un análisis circular y cerrado: la variable dependiente es español y los subgrupos están definidos en función de ella. Además, al tratarse de agrupaciones de centros es lógico pensar que la varianza entre ellos sea menor lo que dificultaría el ajuste de modelos multinivel.
Una posible alternativa es centrar el análisis diferencial estudiando una submuestra compuesta sólo por los dos subgrupos extremos, el 1 y el 9. Al retirar los subgrupos centrales, mediante esta selección nos quedamos sólo con los estudiantes y centros que obtienen puntuaciones más extremas. Aquí sí cabe plantearse un modelo jerárquico lineal, pero en este caso hay una dificultad que radica en que se cuenta con muy pocas unidades del nivel 2. Recordemos que en este caso sólo hay 4 centros en el nodo 1 y 3 en el 2 lo que arroja un total de 7 que es claramente insuficiente para realizar modelización multinivel.
Esto origina que en HLM-5 los modelos multinivel no se desarrollen de forma adecuada pues en los resultados no se muestra el valor de la significación por problemas con los grados de libertad. Ello puede ser debido a este reducido número de elementos del segundo nivel. Así el modelo resulta inestable y además poco convincente (Gaviria y Castro, 2005). O, como afirman Bower y Drake (2005), las estimaciones con menos de 10 grados de libertad en el nivel 2 pueden ser inconsistentes.
En consecuencia, se ha procedido a obtener el modelo sin componentes aleatorios, es decir, aplicando una regresión lineal múltiple. Y los resultados son:
Puntuación en español = 480,66 +
+ 15,11 * Calificación en español en 2º Primaria (0 a 4) +
+ 23,67 * Gusto por la lectura (no = 0, poco = 1, mucho = 2) +
+ 29,27 * Clima escolar (-3 a 2) +
+ 17,69 * NSE Familiar ( -3 a 2,5) -
- 83,14 * Red (pública = 1) -
- 11,78 * Faltas de asistencia del profesor (nunca = 0, a siempre = 3)
El valor de R2 corregida es del 51% y la varianza de los residuos s2 = 7178,60.
Por lo tanto, controlando la calificación en Lengua española en 2º de Secundaria, los resultados del modelo indican que la puntuación media en Lengua española de los estudiantes de 3º de Secundaria de centros privados a los que no les gusta la lectura, cuyo profesor no falta nunca o casi nunca a clase, cuyo NSE familiar es medio, al igual que el clima escolar, es de algo más de 470 puntos (la media es aproximadamente 520 y la desviación típica 120). A ello hay que añadir casi 50 puntos a los estudiantes a los que gusta la lectura. Por su parte, 1 punto de incremento en el Clima escolar según el estudiante (que oscila entre -3 y 2 puntos) origina un incremento de algo más de 30 en Lengua. Por otra parte por cada punto de incremento del NSE familiar, el incremento en la puntuación en Lengua española resulta ser de casi 19 puntos (téngase presente que los valores del NSE Familiar oscilan entre -3 y 2,5 aproximadamente). Estudiar en centros públicos tiene un efecto de disminución en la puntuación en Lengua española de más de 80 puntos en comparación con los privados y 1 punto de incremento en la escala de falta de asistencia del docente conlleva una disminución de casi 12 puntos en el puntaje de lengua.
En este modelo vemos que las variables relevantes son muy similares a las del modelo multinivel para toda la muestra pero ello no es óbice para que entre ambos modelos no deje de haber diferencias reseñables.
Comenzando por las similitudes, se observa que ambos modelos comparten 4 predictores: el gusto por la lectura, el rendimiento previo, el nivel socioeconómico y el clima escolar. A la vista de esto parece clara la relevancia de las cuatro para explicar las diferencias en el desempeño en lengua española. Aquí se han incluido obviamente las variables correspondientes al nivel 1 de los estudiantes.
Pero junto a estas similitudes, también hay algunas diferencias a tomar en consideración. En primer lugar, el sexo de los estudiantes aquí no resulta significativo a pesar de que como se ha comentado en lo relativo al rendimiento en lengua la ventaja de las chicas está ampliamente documentada. En cambio, aparece una variable relativa al cumplimiento formal de los docentes cual es la de la frecuencia de sus faltas de asistencia. Cada incremento de un punto en la escala (que va de 0 a 3) lleva aparejada una disminución de casi 12 puntos en el rendimiento en español. Aunque su nivel de significación está justo en el límite de lo admisible (p=0,05) se incorpora al modelo refrendando lo que ya habían apuntado los modelos de los árboles de decisión, a saber, en los centros extremos los niveles de cumplimiento formal por parte de los docentes tienden también a ser extremos: muy altos en los centros de medias elevadas, muy bajos en los centros de bajo rendimiento.
Estos resultados han de ser tenidos en cuenta con precaución habida cuenta de la imposibilidad de elaborar y validar modelos multinivel para estos subgrupos extremos. Pero parece que existe alguna tendencia a confirmar la hipótesis formulada en el sentido de que en sistemas educativos poco homogéneos conviven realidades sociales muy dispares y, por tanto, los subgrupos extremos tienen un comportamiento diferente al del gran grupo. Sea como sea, parece evidente que es necesario realizar estudios con muestras con mayor número de elementos del nivel 2.
3. Conclusiones
En primer lugar, y tal y como ya se ha señalado, el centro escolar (considerando el turno) como unidad funcional es el elemento clave a la hora de establecer diferencias en el rendimiento en lengua española de los estudiantes. En esta línea, de todas las variables de centro que pueden contribuir a explicar esta capacidad discriminativa, es el nivel socioeconómico medio de los estudiantes que acuden a la escuela la variable que más peso tiene.
Para el caso de la población involucrada en el presente estudio, las variables del turno y tipo de escuela son determinantes en la explicación del rendimiento académico, de forma que los estudiantes de centros privados tienden a obtener un mejor desempeño escolar mientras que los estudiantes que acuden al turno vespertino obtienen los resultados académicos más pobres. Ambas variables son concomitantes con el NSE medio pues los centros privados tienen un NSE medio mayor, mientras que los estudiantes que acuden a realizar sus estudios en horario vespertino presentan un NSE medio inferior.
Continuando con las cuestiones de naturaleza socioeconómica, en la población en edad escolar en Baja California hay un porcentaje importante de estudiantes que declaran trabajar (el 18% en nuestra muestra). Esto se asocia negativamente con el rendimiento académico de forma que en aquellos subgrupos de menor rendimiento la proporción de estudiantes que trabajan es significativamente mayor.
En lo relativo a aspectos de naturaleza escolar o vinculados con la propia actividad educativa, se cuenta con evidencia que apunta en la misma dirección que los resultados de diversos estudios con propósitos similares, de forma tal que variables como el gusto por la lectura o un clima escolar favorable, se asocian con calificaciones altas en lengua española.
Por último, en lo relativo al cumplimiento formal de docentes y estudiantes (faltas de asistencia, puntualidad, etc.), éstas resultan tener una alta capacidad explicativa pero sólo para algunos subgrupos con estudiantes con calificaciones bajas o muy bajas.
En el sistema educativo de Baja California conviven realidades sociales, culturales y económicas muy heterogéneas. Esto hace que las diferencias entre centros escolares sean muy acusadas de forma que junto a centros escolares de muy alto nivel nos encontramos con otros que se encuentran en el otro extremo de la escala. Esto dificulta el diseño y ajuste de un único modelo para analizar realidades sociales tan dispares, pues junto con los indicadores y predictores que tienen una alta capacidad explicativa en todos los subgrupos y niveles, nos encontramos con otras variables que tienen también una alta incidencia y capacidad explicativa pero sólo en algunos subgrupos de algunos niveles, habitualmente en los nodos extremos.
En las escuelas de muy bajo nivel socioeconómico medio, las oportunidades de aprendizaje de sus estudiantes no radican tanto en disponer de ordenadores o en estar conectados a la red. El asunto es más sencillo y elemental: como primera condición basta con que los profesores y estudiantes acudan a clase con regularidad y puntualidad llevando a cabo unos y otros las tareas encomendadas tendentes al cumplimiento efectivo del currículo.
Baja California, y nos atreveríamos a decir que México en su conjunto es un país complejo con una realidad social también compleja que hace que coexistan centros perfectamente equiparables a los de nivel socioeconómico alto de los países desarrollados, con otras situaciones y centros propios de países en vías de desarrollo.
En nuestra opinión, tanto desde un punto de vista centrado en la elaboración y ajuste de modelos explicativos del rendimiento académico como en aquel que priorice el diseño y puesta en marcha de acciones y programas de mejora es muy importante tomar en consideración este efecto diferencial. Es preciso considerar estas variables que operan como oportunidades de aprendizaje sólo en algunos subgrupos aunque sean pequeños y extremos, porque en caso contrario para estos sectores de la población (que son los más desfavorecidos) los modelos generales y las acciones de mejora que eventualmente se puedan diseñar y en su caso aplicar estarán desenfocados y por tanto no resultarán de utilidad.
Referencias Bibliográficas
Backhoff, E., Bouzas, A., Hernández, E. y García, M. (2007). Aprendizaje y desigualdad social en México. Implicaciones de política educativa en el nivel básico. México: INEE.
Backhoff, E., Bouzas, A., Contreras, C., Hernández, E. y García, M. (2007). Factores escolares y aprendizaje en México. El caso de la educación básica. México: INEE.
Backhoff, E., Andrade, E., Sánchez, A. y Peón, M. (2008). El aprendizaje en tercero de preescolar en México. México: INEE.
Barrera, O. (2009). La Evaluación de la Educación Cívica y Ética en México. Un Recorrido por 3º de Primaria y 3º de Secundaria. Revista Iberoamericana de Evaluación Educativa, 2 (1), pp.114-129. Consultado el 10 de octubre de 2010 en http://www.rinace.net/riee/numeros/vol2-num1/art6.pdf.
Biggs, D.B. de Ville and Suen, E. (1991). A method of choosing multiway partitions for classification and decision trees. Journal of Applied Statistics. 18, pp.49-62.
Bowers, J., Drake, K. W. (2005). EDA for HLM: Visualization when Probabilistic Inference Fails. Political Analysis, 13(4), pp. 301-326.
Carvallo, M., Caso, J. and Contreras, L.A.(2007). Estimación del efecto de variables contextuales en el logro académico de estudiantes de Baja California. Revista Electrónica de Investigación Educativa, 9 (2). Consultado el 8 de abril de 2010 en http://redie.uabc.mx/vol9no2/contenido-carvallo.html.
Caso, J., Hernández, E. y Rodríguez, J.C. (2009). Análisis Multinivel de los Factores Asociados a la Educación Cívica en Estudiantes de Secundaria. Revista Iberoamericana de Evaluación Educativa, 2 (1), pp. 226-238. Consultado el (Fecha) en http://www.rinace.net/riee/numeros/vol2-num1/art12.pdf.
Dudley, W., Dilorio, C., Soet, J. (2000). Detecting and explicating interactions in categorical data. Nursing-Research, 49(1), pp. 53-56.
Gaviria, J.L., Castro, M. (2005). Modelos jerárquicos lineales.Madrid: Ed. La Muralla.
Howley, C. B. and Howley, A.A. (2004). School size and the influence of socioeconomic status on student achievement: Confronting the threat of size bias in national data sets. Education Policy Analysis Archives, 12(52). Recuperado de http://epaa.asu.edu/epaa/v12n52/.
Kass, G. (1980). An exploratory technique for investigating large quantities of categorical data. Applied Statistics. 29(2), pp.119-127.
Lizasoain, L., Joaristi, L., Lucas, J.F., Santiago, C. (2007). El efecto contextual del nivel socioeconómico sobre el rendimiento académico en la Educación Secundaria Obligatoria. Estudio diferencial del nivel socioeconómico familiar y del centro. Education Policy Analysis Archives, 15(6), pp. 1-25.
Lizasoain, L., Santiago, C., Moyano, N., Munarriz, B., Joaristi, L., Lucas, J.F., Sedano, M. (2003). El uso de Las Técnicas de Segmentación en la evaluación del rendimiento de Lenguas. Un estudio en la Comunidad Autónoma Vasca. Revista de Investigación Educativa, 21(1), pp. 93- 111.
Ruíz, G. (2009). La Calidad del Sistema Educativo Mexicano desde los Resultados de Evaluaciones Nacionales. El Aprendizaje en Matemáticas. Revista Iberoamericana de Evaluación Educativa, 2 (1), pp. 74-89. Consultado el 10 de octubre de 2010 en http://www.rinace.net/riee/numeros/vol2-num1/art4.pdf.
Rumberger, R., and Willms, J.D. (1992). The impact of racial and ethnic segregation on the achievement gap in California high schools. Educational Evaluation and Policy Analysis, 14(4), pp. 337-396.
Sánchez, A. (2009). La Evaluación del Logro Escolar en la Educación Básica en México. Los Excale de Matemáticas. Revista Iberoamericana de Evaluación Educativa, 2(1), pp. 186-204. Consultado el 10 de octubre de 2010 en http://www.rinace.net/riee/numeros/vol2-num1/art10.pdf.
Santiago, C., Lucas, J.F., Joaristi, L., Lizasoain, L., Moyano, N. (2008). A longitudinal Study of Academic Achievement in Spanish: The Effect of Linguistic Models. Language, Culture And Curriculum, 21(1), pp. 48-58.
Tajalli, H. and Opheim, C. (2004). Strategies for Closing the Gap: Predicting Student Performance in Economically Disadvantaged Schools. Educational Research Quarterly 28(4), pp.44-54.
Valenti, G. (2007) Factores asociados al logro educativo de matemáticas y español en la Prueba ENLACE 2007. México: SEP.
Warschauer, M., Knobel, M. and Stone, L. (2004). Technology and Equity in Schooling: Deconstructing the Digital Divide. Educational Policy, 18(4), pp. 562-588.
Willms, J.D. (1986). Social Class Segregation and Its Relationship to Pupil’s Examination Results in Scotland. American Educational Review 51(2), pp.224-241.
Willms, J.D. (2003). Ten Hypotheses about Socioeconomic Gradients and Community Differences in Children’s Developmental Outcomes. Final Report. Applied Research Branch. Strategic Policy. Human Resources Development. Canada. Consultado el 26 de abril en http://www.hrdc-drhc.gc.ca/sp-ps/arb-dgra.
Willms, J.D. (2004). Reading Achievement in Canada and the United States: Findings from the OECD Programme of International Student Assessment. Final Report. Learning Policy Directorate Strategic Policy and Planning Human Resources and Skills Development. Canada. Consultado el 25 de abril en http://www.hrsdc-rhdcc.gc.ca/sp-ps/arb-dgra.
Willms, J.D. (2006). Learning Divides: Ten Policy Questions About The Performance And Equity Of Schools And Schooling Systems. Montreal: UNESCO Institute for Statistics.
{1} Este trabajo ha sido realizado en el contexto del proyecto titulado Estrategia integral 2009: factores asociados al aprendizaje, financiado por el Sistema Educativo Estatal de Baja California y coordinado por la Unidad de Evaluación Educativa de la Universidad Autónoma de Baja California.
{2} En el caso del coautor Luis Lizasoain, esta investigación se realizó en el contexto de una estancia sabática durante el curso 2009-2010 en la Universidad Autónoma de Baja California para la que se dispuso de financiación mediante una subvención del subprograma de estancias de movilidad de profesores e investigadores españoles en centros extranjeros, modalidad A; concedida por el Ministerio Español de Educación.